
We’re familiar with AI tools and large language models (think chatGPT), but there are also smaller language models that have distinctive and highly useful features. I am not quite sure “small” is the right adjective, as these models are still, well, large — the files for those I’ve been using are a few GB in size, and developing the models still takes ridiculously abundant resources. But, they’re a heckuva lot smaller than models like those behind chatGPT, they are freely downloadable, and, critically, you can run them exclusively on a laptop computer without access to the Internet, and with no sharing of your data in any form with any company.
Let me give an example. I’ve been playing with these tools a lot. I’ve been using the LM Studio software, which lets you download one or more models — small, especially, but some quite large. Below, for instance, see some information on an “open source” model (from, well, Meta), Llama-3.1. You can see the model is 4.92 GB.
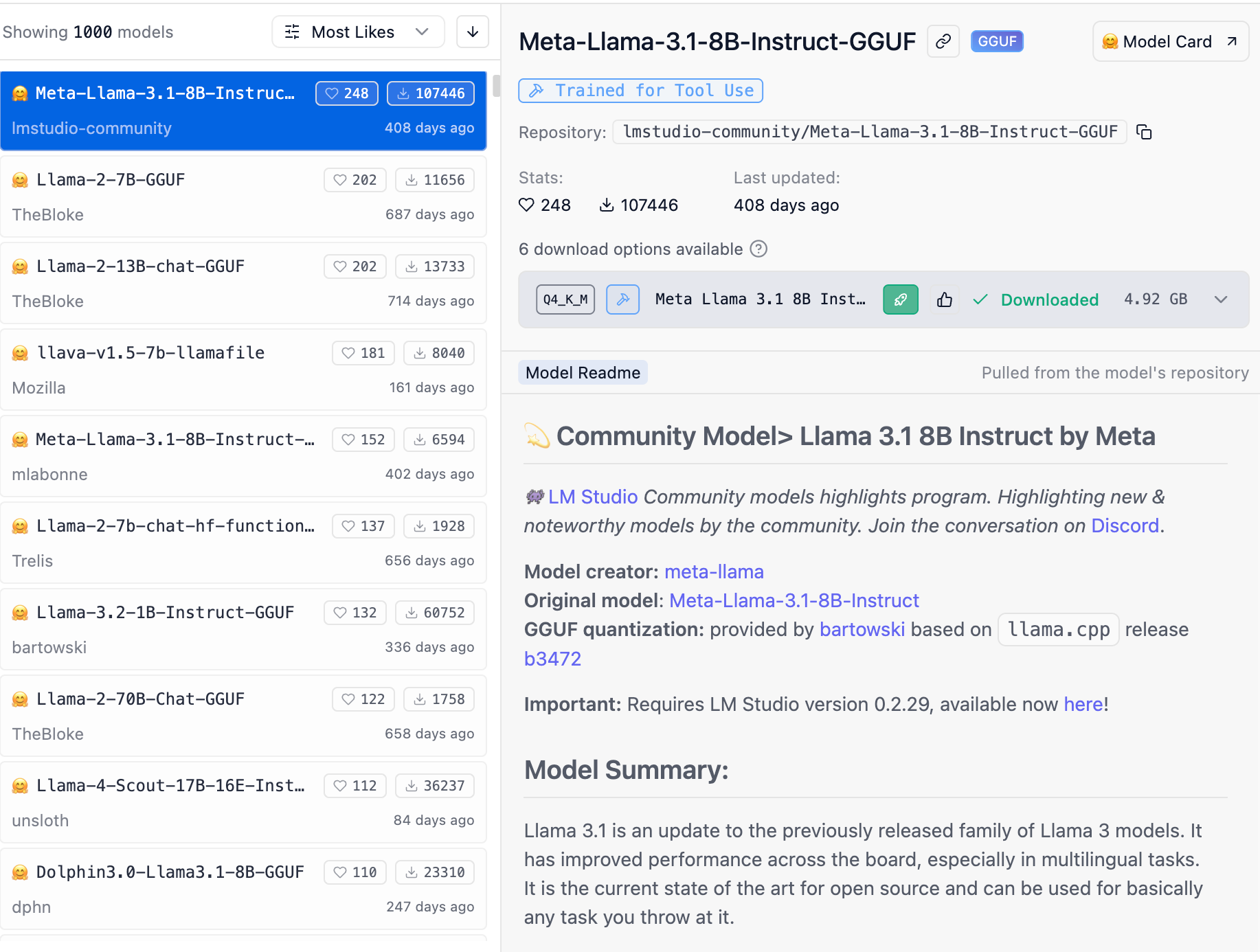
After downloading it, you can, well, use it! Let’s ask what it thinks of being small…
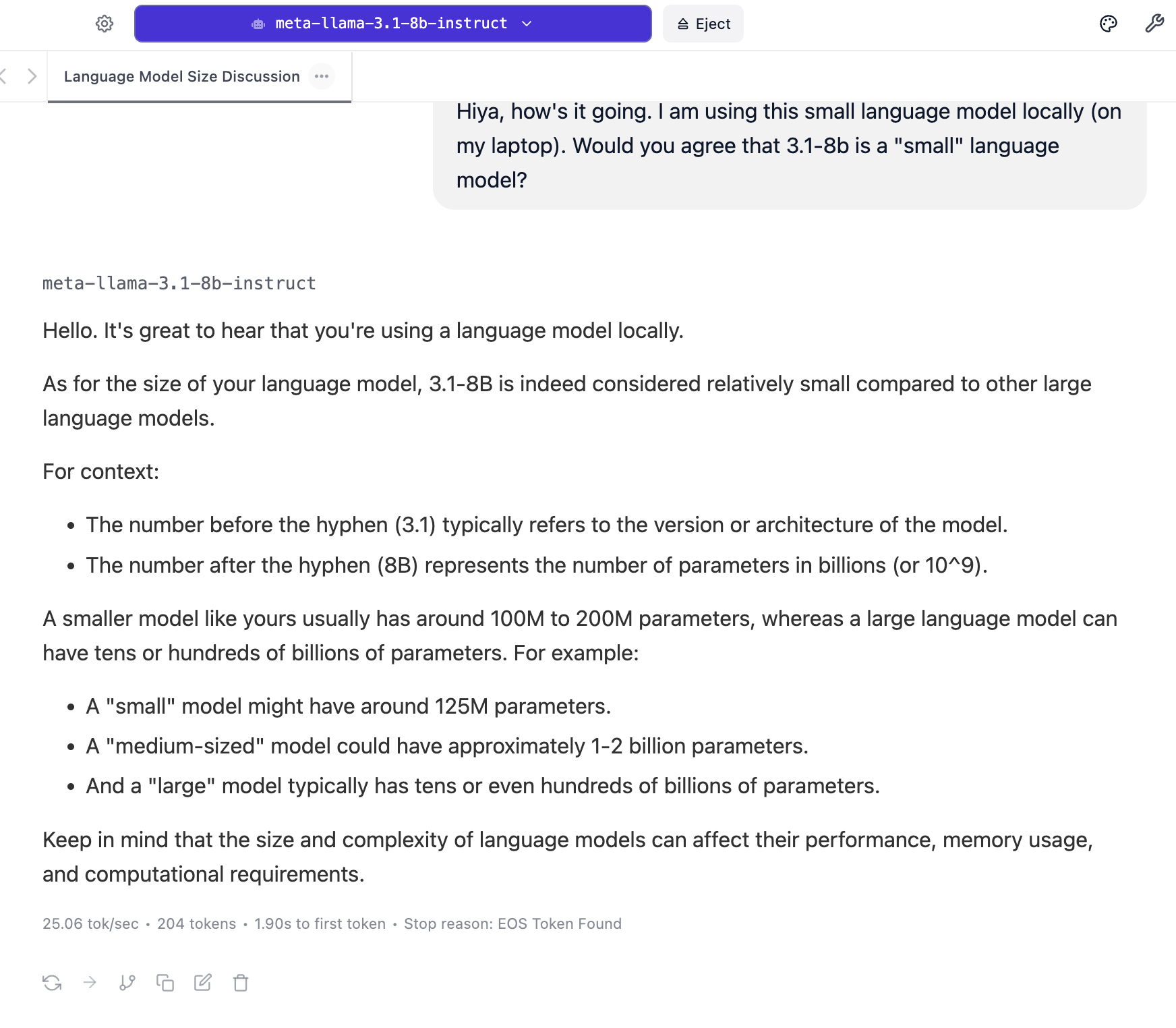
The advantage here is if you have research data, for instance, you in many cases cannot upload this data to chatGPT and its servers — it would violate our consent process and Institutional Review Board protocol for human subjects research. In short, we can’t share private data with chatGPT. But, as long as we can confirm that zero data is being shared back to LM Studio and Meta (or the creators of any model we use), we can use one of these small language models. For instance, I recently used the model above to write one paragraph summaries to help us to be able to select and more carefully read transcripts of the audio from a recent workshop with teachers. I am also exploring using them to match names from parent consents and student assents.
So, small language models may be useful for a lot of tasks that one could use chatGPT for if data privacy were not an issue (for research, it is). There’s one last cool aspect of these small language models — you can program with them.
Click the button on the “developer” tab to turn on “server mode”.
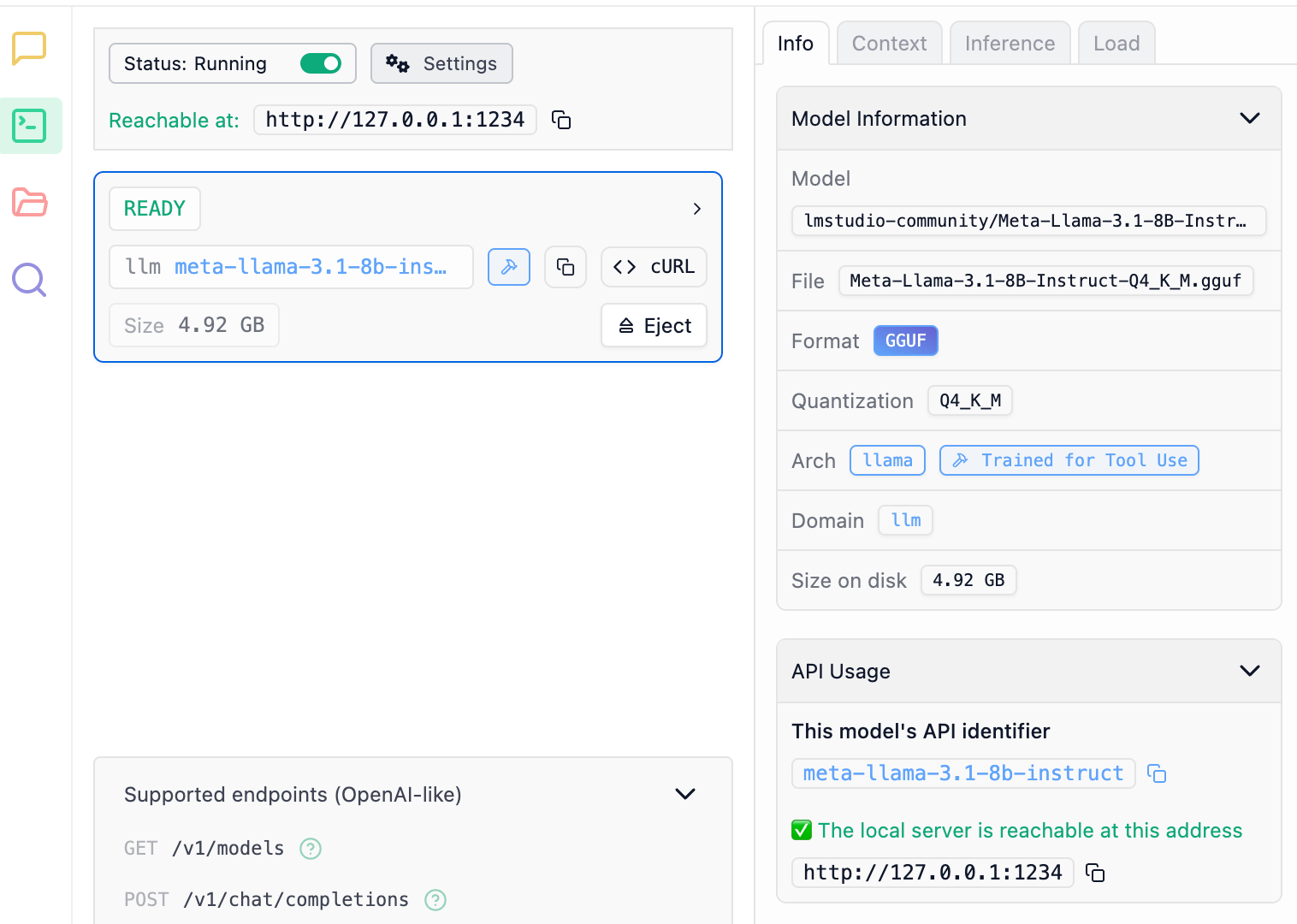
Then, a sipmle little python code snippet lets you interact with it through, well, code.
import requests
url = "http://localhost:1234/v1/chat/completions"
headers = {"Authorization": "Bearer lm-studio", "Content-Type": "application/json"}
payload = {
"model": "meta-llama-3.1-8b-instruct",
"messages": [{"role": "user", "content": "Say hi from Knoxville!"}],
}
r = requests.post(url, headers=headers, json=payload)

The magic here is that when we can interact through code, we can try creative things, like sending hundreds, thousands, or tens of thousands (or more) transcripts to the small language model to summarize. In this way, we can do things that are difficult to do simply by copying and pasting text into chat — like analyzing data or building a tool or app that uses the small language model.
In short, small language models are awesome (for research, especially), and underrated relative to the more fancy models we can use through services like chatGPT.
Thanks to my friend Marcus Kubsch for making me aware of LM Studio more than a year ago.